
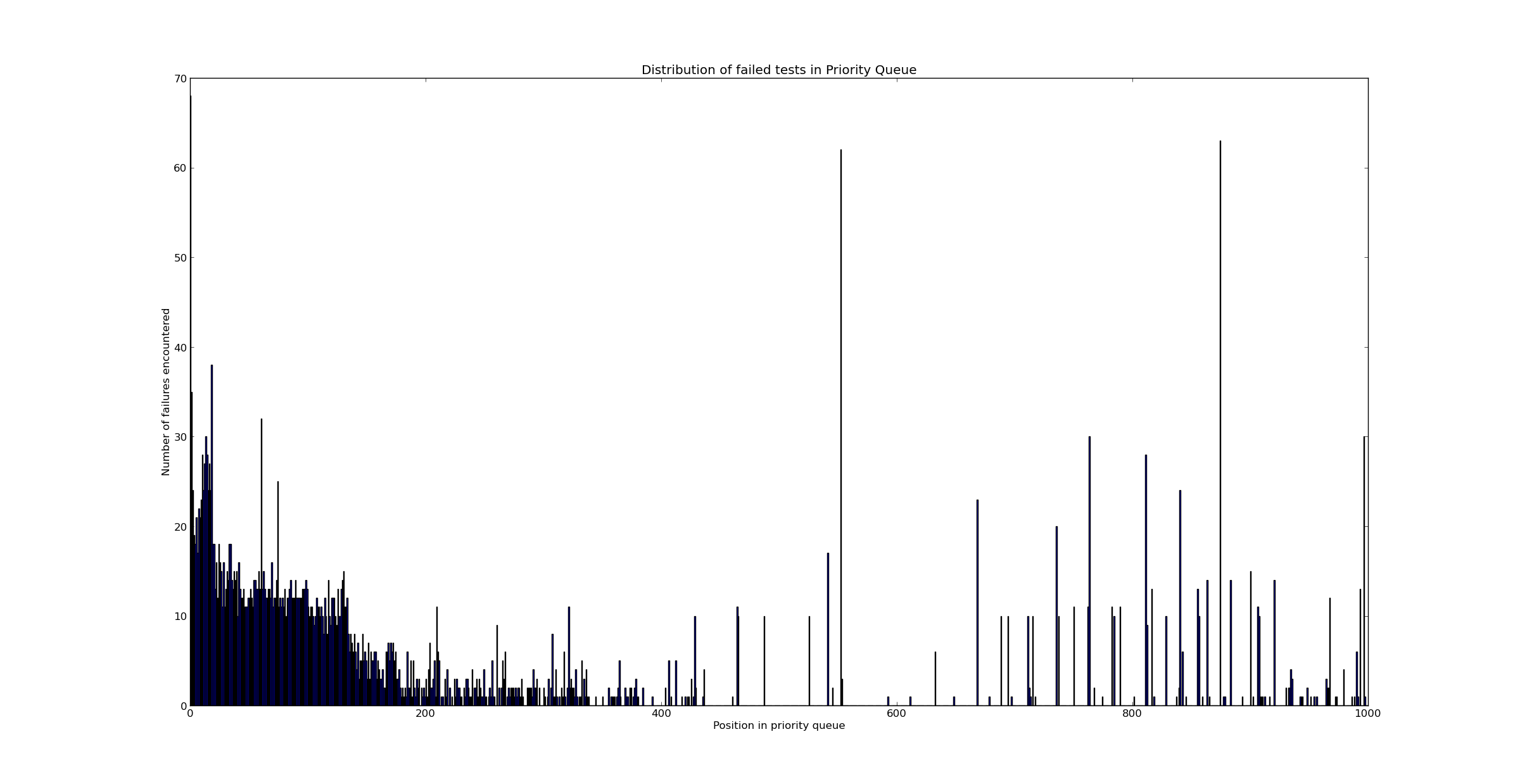
Hello everyone, I took the last couple of days working on a new strategy to calculate the relevance of a test. The results are not sufficient by themselves, but I believe they point to an interesting direction. This strategy uses that rate of co-occurrence of events to estimate the relevance of a test, and the events that it uses are the following: - File editions since last run - Test failure in last run The strategy has also two stages: 1. Training stage 2. Executing stage In the training stage, it goes through the available data, and does the following: - If test A failed: - It counts and stores all the files that were edited since the last test_run (the last test_run depends on BRANCH, PLATFORM, and other factors) - If test A failed also in the previous test run, it also counts that In the executing stage, the training algorithm is still applied, but the decision of whether a test runs is based on its relevance, the relevance is calculated as the sum of the following: - The percentage of times a test has failed in two subsequent test_runs, multiplied by whether the test failed in the previous run (if the test didn't fail in the previous run, this quantity is 0) - For each file that was edited since the last test_run, the percentage of times that the test has failed after this file was edited (The explanation is a bit clumsy, I can clear it up if you wish so) The results have not been too bad, nor too good. With a running set of 200 tests, a training phase of 3000 test runs, and an executing stage of 2000 test runs, I have achieved recall of 0.50. It's not too great, nor too bad. Nonetheless, while running tests, I found something interesting: - I removed the first factor of the relevance. I decided to not care about whether a test failed in the previous test run. I was only using the file-change factor. Naturally, the recall decreased, from 0.50 to 0.39 (the decrease was not too big)... and the distribution of failed tests in the priority queue had a good skew towards the front of the queue (so it seems that the files help somewhat, to indicate the likelihood of a failure). I attached this chart. An interesting problem that I encountered was that about 50% of the test_runs don't have any file changes nor test failures, and so the relevance of all tests is zero. Here is where the original strategy (a weighted average of failures) could be useful, so that even if we don't have any information to guess which tests to run, we just go ahead and run the ones that have failed the most, recently. I will work on mixing up both strategies a bit in the next few days, and see what comes of that. By the way, I pushed the code to github. The code is completely different, so may be better to wait until I have new results soon. Regards! Pablo
{kind=link}