
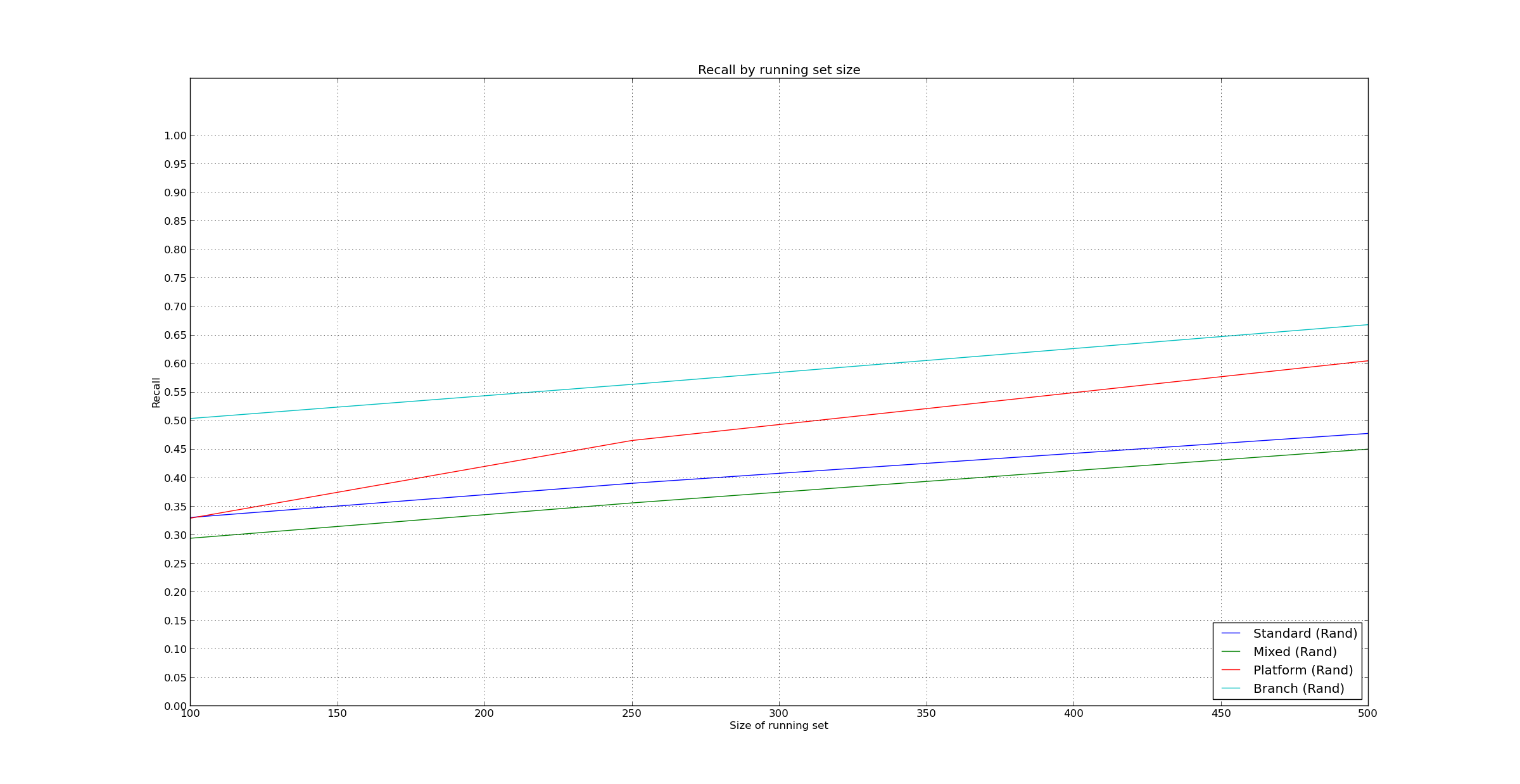
Hello Elena, Here's what I have to report: 1. I removed the getLogger function from every called. It did improve performance significantly. 2. I also made sure that only the priority queues that concern us are built. This did not improve performance much. 3. Here are my results with 50,000 test runs with randomization, test_edit_factor and time_factor. They are not much better. (Should I run them without randomization or other options?) 4. I started with concepts and a bit of code for a new strategy. I am still open to work with the current codebase. Here are results using 47,000 test_run cycles as training, and another 3,000 for predictions. They don't improve much. My theory is that this happens because they are really linear: They only leverage information from very recent runs, and older information becomes irrelevant quickly. I started coding a bit of a new approach, looking at correlation between events since last test run and test failures. So for instance: - Correlation between files changed and tests failed - Correlation between failures in the last test run and the new one (tests that fail several times subsequently are more relevant) I just started, so this is only the idea, and there is not much code in place. I believe I can code most of it in less than a week. Of course, I am still spending time thinking how to improve the current strategy, and am definitely open to any kind of advice. Please let me know your thoughts. Regards Pablo On Mon, Jun 23, 2014 at 1:08 AM, Pablo Estrada <polecito.em@gmail.com> wrote:
Hi Elena, I ran these tests using the time factor but not the test edit factor. I will make the code changes and run the test on a bigger scale then. I will take a serious look through the code to try to squeeze out as much performance as possible as well : )
Regards Pablo On Jun 23, 2014 1:01 AM, "Elena Stepanova" <elenst@montyprogram.com> wrote:
Hi Pablo,
Thanks for the update. I'm looking into it right now, but meanwhile I have one quick suggestion.
Currently your experiments are being run on a small part of the historical data (5% or so). From all I see, you can't afford running on a bigger share even if you want to, because the script is slow. Since it's obvious that you will need to run it many more times before we achieve the results we hope for, it's worth investing a little bit of time into the performance.
For starters, please remove logger initialization from internal functions. Now you call getLogger from a couple of functions, including the one calculating the metric, which means that it's called literally millions of times even on a small part of the data set.
Instead, make logger a member of the simulator class, initialize it once, e.g. in __init__, I expect you'll gain quite a lot by this no-cost change.
If it becomes faster, please run the same tests with e.g. ~50% of data (learning set 47,000 max_count 50,000), or less if it's still not fast enough. No need to run all run_set values, do for example 100 and 500. It's interesting to see whether using the deeper history makes essential difference, I expect it might, but not sure.
Please also indicate which parameters the experiments were run with (editing and timing factors).
Regards, Elena
On 22.06.2014 18:13, Pablo Estrada wrote:
Hello everyone, I ran the tests with randomization on Standard and Mixed mode, and here are the results. 1. Standard does not experience variation - The queue is always long enough. 2. Mixed does experience some variation - Actually, the number of tests run changes dramatically, but I forgot to add the data in the chart. I can report it too, but yes, the difference is large. 3. In any case, the results are still not quite satisfactory, so we can think back to what I had mentioned earlier: How should we change our paradigm to try to improve our chances?
Regards Pablo
On Fri, Jun 20, 2014 at 7:45 PM, Pablo Estrada <polecito.em@gmail.com> wrote:
I have pushed my latest version of the code, and here is a test run that
ran on this version of the code. It is quite different from the original expectation; so I'm taking a close look at the code for bugs, and will run another simulation ASAP (I'll use less data to make it faster).
On Thu, Jun 19, 2014 at 5:16 PM, Elena Stepanova < elenst@montyprogram.com> wrote:
Hi Pablo,
I'll send a more detailed reply later, just a couple of quick comments/questions now.
To your question
I'm just not quite sure what you mean with this example:
mysql-test/plugin/example/mtr/t
In this example, what is the test name? And what is exactly the path? (./mysql-test/...) or (./something/mysql-test/...)? I tried to look at some of the test result files but I couldn't find one certain example of this pattern (Meaning that I'm not sure what would be a real instance of it). Can you be more specific please?
I meant that if you look into the folder <tree>/mysql-test/suite/mtr/t/ , you'll see an example of what I described as "The result file can live not only in /r dir, but also in /t dir, together with the test file":
ls mysql-test/suite/mtr/t/ combs.combinations combs.inc inc.inc newcomb.result newcomb.test proxy.inc self.result self.test simple,c2,s1.rdiff simple.combinations simple.result simple,s2,c2.rdiff simple,s2.result simple.test single.result single.test source.result source.test test2.result test2.test testsh.result testsh.test
As far as I remember, your matching algorithm didn't cover that.
Here are the results. They are both a bit counterintuitive, and a bit
strange
Have you already done anything regarding (not) populating the queue completely? I did expect that with the current logic, after adding full cleanup between simulations, the more restrictive configuration would have lower recall, because it generally runs much fewer tests.
It would be interesting to somehow indicate in the results how many tests were *actually* run. But if you don't have this information, please don't re-run the full set just for the sake of it, maybe run only one running set for standard/platform/branch/mixed, and let us see the results. No need to spend time on graphs for that, a text form will be ok.
Either way, please push the current code, I'd like to see it before I come up with any suggestions about the next big moves.
Regards, Elena
{kind=link}