
Hi Elena, Thanks. I hoped you would have results of the experiments involving
incoming lists of tests, as I think it's an important factor which might affect the results (and hence the strategy); but I'll look at what we have now.
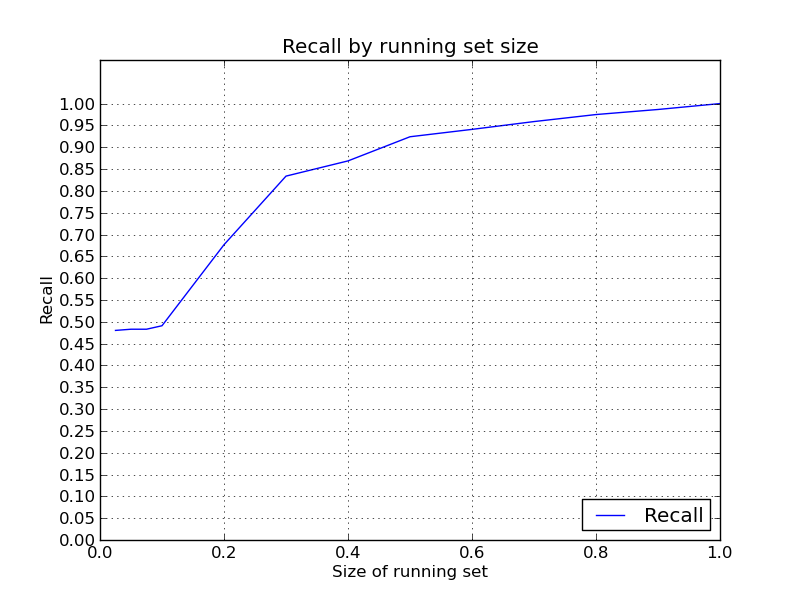
I have them now. There was one more bug I hadn't figured out. There are still a couple bugs related to matching of input test list, but these results must be quite close to the expected ones. I did them with 3000 rounds of training, and about 1500 rounds of prediction (skipping all runs without input list). Although the results are not as originally expected (20-80 ratio, I feel that they are quite acceptable. I will see what we can do about getting reliable lists one or another way;
certainly the log files are a temporary solution, but it would be nice to use them for experiments and see the results anyway, because modifying MTR/buildbot tandem and especially collecting the new data of considerable volume will take time.
I understand, nonetheless I feel that this is a reasonable long-term goal for this project.
This is not to say that parsing logs is the best way to do things, but apparently something went wrong either with my archiving or with your matching. If you don't have these files, please let me know.
It seems there's a bug with matching. I am looking at it now. I've uploaded the fresh dump. Same location, file name
buildbot-20140722.dump.gz.
I will run more detailed tests with the new fresh dump. I will focus on a running set size of 30%. I believe they will be reasonable.
Thanks. Pablo
{kind=link}