
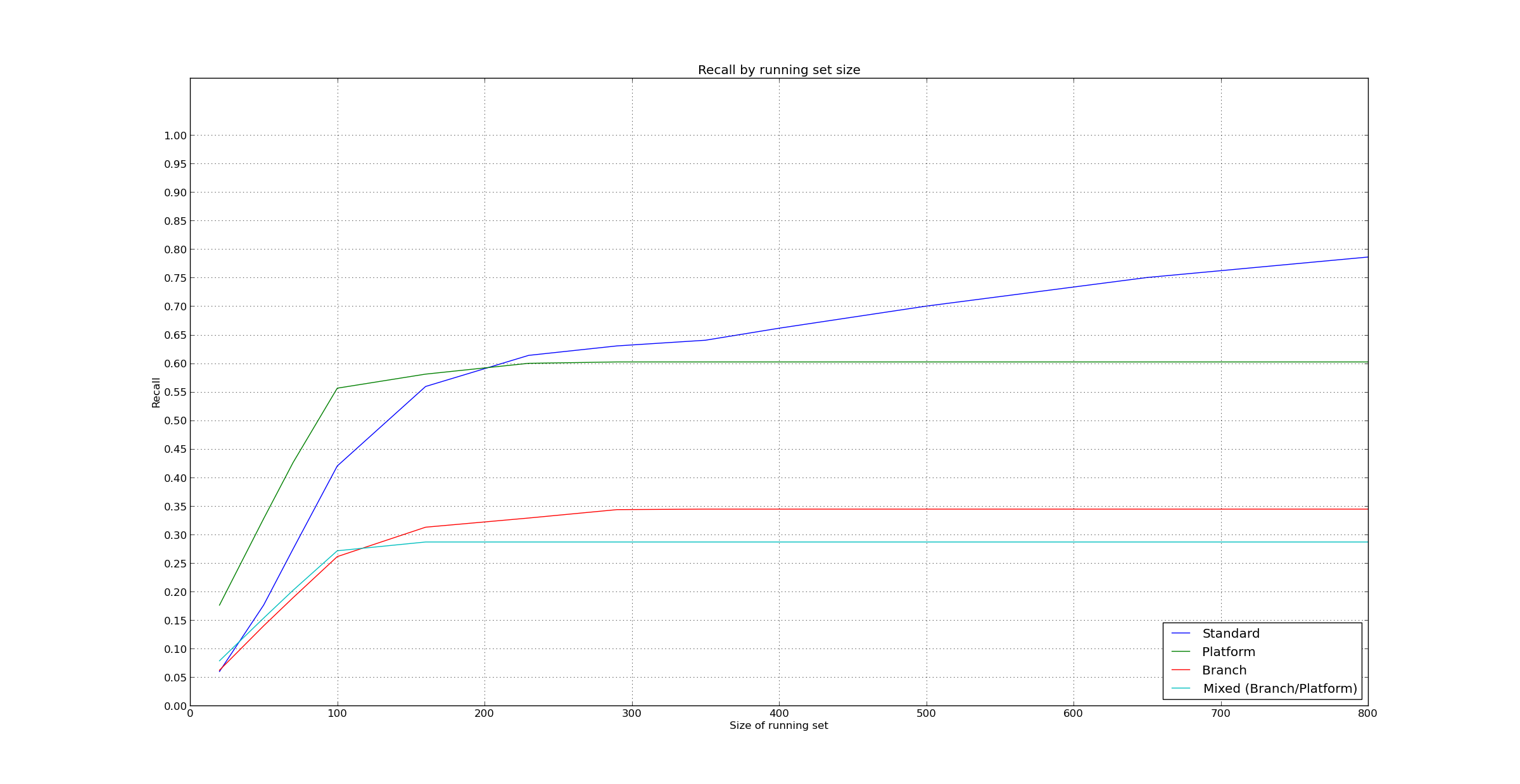
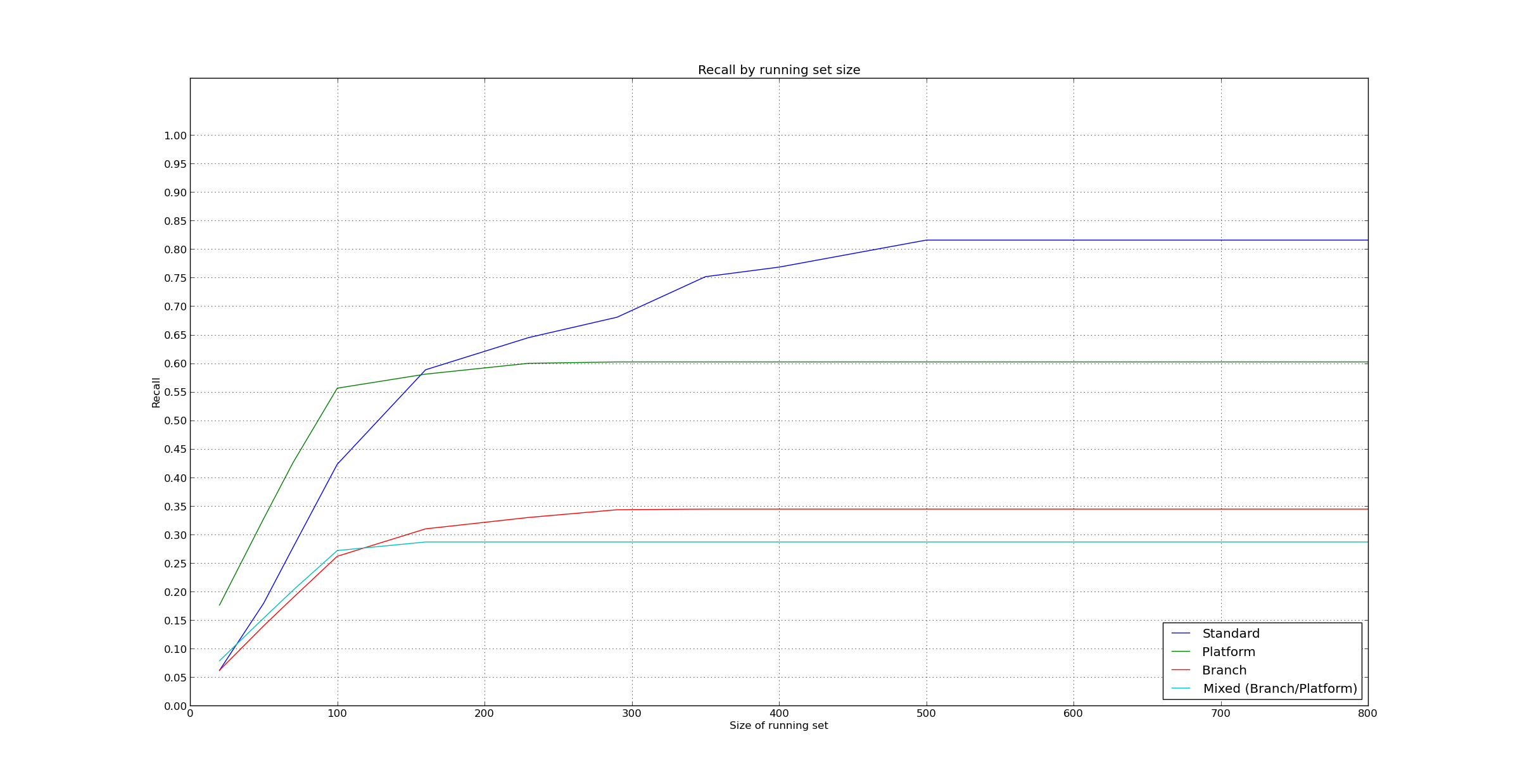
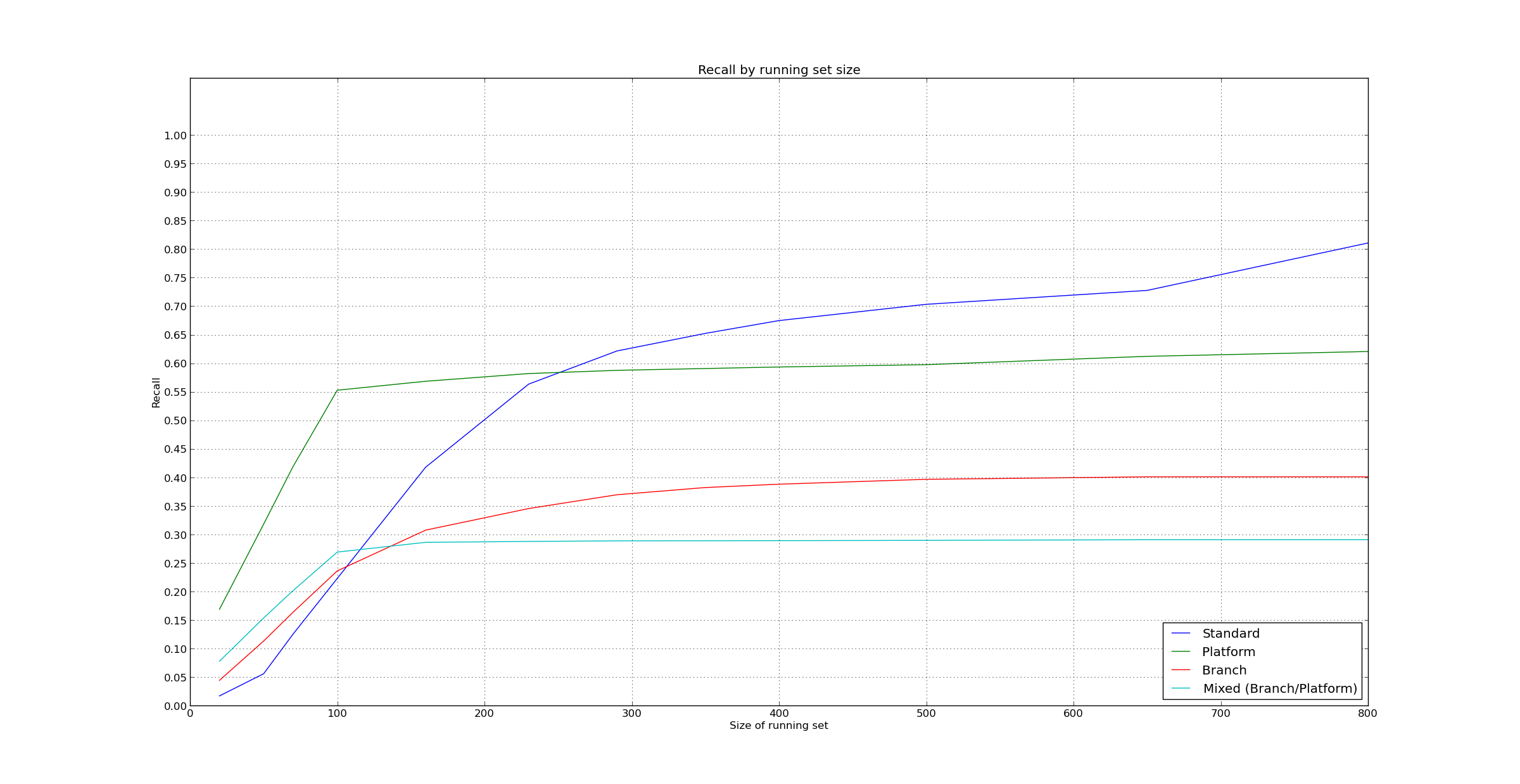
Hello everyone, I'll start with the more trivial content: I am fixing the logic to match test result files with test names. I already fixed the following cases that you provided, Elena: ./mysql-test/suite/engines/iuds/r/delete_decimal.result mysql-test/suite/mtr/t/ ./storage/tokudb/mysql-test/suite/tokudb/r/rows-32m-1.result ./storage/innodb_plugin/mysql-test/innodb.result I'm just not quite sure what you mean with this example: mysql-test/plugin/example/mtr/t In this example, what is the test name? And what is exactly the path? (./mysql-test/...) or (./something/mysql-test/...)? I tried to look at some of the test result files but I couldn't find one certain example of this pattern (Meaning that I'm not sure what would be a real instance of it). Can you be more specific please? Now, the more *serious issue*: Here are the results. They are both a bit counterintuitive, and a bit strange; but that's what I received. Basically, it seems that less is more, and recall gets worse as we add more detailed metrics. I ran the simulations only for 5000 test_runs, but I can also run them with more, and see what comes out of that. By the way, just to be sure, I recreated the objects every new simulation, so there is no doubt regarding the dependency between simulations in this case. (Although I implemented a cleanup function as well, and I'll push the final version soon). In any case, I don't think the results are good enough even in the best case... so maybe we'd want to explore more strategies. What do you guys think? I feel that going on with the same model, we can get back to the correlations between test failures. I already have a local branch in my repository where I started experimenting with this, so it should not take long to perfect that code. I can try this. If we want to be a bit more adventurous, we can also observe correlation between file changes and test failures. If we want to incorporate correlation between file changes and test failures, we can base everything in correlations, and make it a more probabilistic model: In the learning phase collect probabilities that each test fails given the 'events' that occurred since the last test run (for example files that changed, test files that changed, and tests that failed the last time). This will build a set of *probabilities*, and we run the tests that have the highest 'p*robabilities *to fail in this run. The probabilities are updated as new test_runs happen, and the data and model are updated. (We can use a decay algorithm, or we can let the probabilities decay on their own as correlations between events and test failures shift)... Of course, this idea is is more 'disruptive', would take a lot more time to code, and it has a bigger risk (since we don't have any warranties of the results).... also, it is probably more complex, computationally.... Maybe I should focus on fixing all possible bugs in my code right now, but on the other hand, I don't think that will improve results dramatically. What do you guys think? In summary: - I am fixing the logic to convert test result file, can you clarify your last example Elena? (See top of email) - The results are close to 60% for 200 tests. How's that? - Once I've fixed the issues pointed out by Elena, I will start working on correlation between test failures, to see if that helps at all. - Considering a very different strategy to try to improve results. How's that? Regards Pablo On Tue, Jun 17, 2014 at 5:40 PM, Elena Stepanova <elenst@montyprogram.com> wrote:
Hi Pablo,
One more note:
On 17.06.2014 12:16, Pablo Estrada wrote:
- Add randomized running of tests that have not ran or been modified
- I will make this optional.
I think it will be very useful for the *research* part if you make the seed for this randomization deterministic for every particular test run (or make it configurable); e.g. you can use the timestamp of the test run as a seed. This way you will keep results invariant. Otherwise when you run consequent experiments with the same parameters, you will be getting different results, which might be confusing and difficult to interpret.
Regards, Elena
{kind=link}
{kind=link}
{kind=link}